Exploratory study of some acoustic and articulatory characteristics of sad speech¶
| Authors: | Donna Erickson and Kenji Yoshida and Caroline Menezes and Akinori Fujino and Takemi Mochida and Yoshiho Shibuya, |
|---|---|
| Jounal: | Phonetica vol. 63, no. 1, pp. 1-25, 2006.0, |
| Tags: | プロポーザル; 感情音声 |
注釈
本研究では二人の女性(日本人とアメリカ人)の気軽な電話会話における自発的に発話された感情音声の音響と EMA データ による調音データを調査したものである。 発話者を真似たり、オリジナルの感情発話を読み上げたコントロールデータも収録した。 アメリカ人を対象に情報パターンを真似さている。 結果は以下の三点を示唆している。
- 自発的悲しみ音声は音響的、調音的特徴に読み上げ音声や感情模倣音声とは異なる。
- 自発的悲しみ音声と悲しみ模倣音声は音響的には同じような性質をしている(高い F0 や声質としての F1 の変化)が、調音構造として唇や顎、舌の位置が異なる。
- 高い F0 や声質の変化は悲しみとして聞き手が判断する音声と相関がある。
Contents
Introduction¶
発話者が伝えたいものは構文的な音素や語の言語的ユニットだけではなく、F0 や持続時間、強度や声のトーン、リズムやフレージングを含む発話者の声の音響的変化である。 Eldred and Price [1958] で述べたように、コミュニケーションは ‘何’ を言っているのかのみが含まれているのではなく、’どのように’ 言っているのかもふくまれている。 Fujisaki [2004] では ‘パラ言語情報’ として言及される’どのように’ 関する情報形式には 書き言葉によって伝達される離散的で、カテゴリカルな ‘言語的情報’ と 発話者の性別、年齢、感情などに基本的には左右されない情報である、非言語情報との二つがあることを示唆している。 感情、指標的、社会的、文化的、そして言語的情報を含む様々な種類の音声信号によって伝達される情報の並行通信は Bühler [1934]からある言語学の伝統的命題である。 表情豊かな音声の多重複合性の豊かさに関する様々な研究のレビューとしては、Schroeder [2004], Gobl and Ní Chasaide [2003], Douglas-Cowie et al.[2003] などを参照されたい。
聞き手の認識を評価することを含む、表情豊かな音声の複雑な性質を研究するための1つのアプローチは、 静的なものではなく、何か継続的に時間変化するものである。 感情/効果を形容詞や尺度を使って記述するものではなく、 寧ろ、Cowie et al. [2000] や Schroeder [2004] に記述されているように 例えば感情の大きさや、活性度(能動的、受動的), 評価(ネガティブ、ポジティブ) などを 聞き手に 例えば ‘Feeltrace’ などの グラフィカルインターフェースを使い評価するように求める。 ある場合にはその後, 主成分分析(PCA)などの統計解析を行い、 ある感情尺度の知覚が、どの音響的(または調音的)特性と関連しているのかを決定する。 これらの線の間で「自由な選択指標」を使うことができる[see, e.g., Campbell and Erickson, 2004]. この研究では、一人の話者から発話された 「えー」(日本語のバックチャンネリング発話) という音声を被験者に提示し, 音声をコンピュータスクリーン上にあるボックスに並べることを求めた. その後、被験者が音を知覚する方法に応じてボックスにラベルを割り当てた。 ついで、PCA を応答の基礎となる関係を決定するために行った。
その他、表情豊かな音声を研究するためによく使われる方法は、 聞き手や実験者により付与される幸せや、悲しみ、怒りなどの感情形容詞ラベルを使用したある特定の感情表現と音響や調音特性を調査することである。 様々な研究は音響的変化は特定の感情/効果に影響を及ぼすことを報告している[see e.g., review articles by Scherer,2003; Gobl and Ní Chasaide, 2003; Erickson, 2005].
明瞭度も効果に影響する。 例えば、Maekawa et al. [1999] や Erickson et al. [2000] では 発話者が異なったパラ言語的状況、例えば、疑いや賞賛、怒りなどで同じ発話を発話した もらった場合舌や顎の位置は変化することを明らかにした。
特定の感情を要求されて話し手が発話するような演技音声と自発的感情表現を区別することが重要である。 演技された感情は特定の影響を聞き手に伝えようと声優は口頭表現を制御するため、 演技音声は発話者により、これらの感情が経験されるものとは別のカテゴリになる場合が多い。 例えば、深い悲しみを表現するためにある話者は発話中に泣き始めるかもしれない。 泣くことは言語的メッセージの一部ではない。 一般に発話者は泣くことを制御できない。 これはしばしば、発話者の意図に拘わらずおき、生理的感情的に脳内で誘発された変化の結果である. Brown et al. [1993] のような研究では悲しみや高揚の結果としてのホルモン変化を示している。 悲しみや高揚など特定の感情による発話者の生物学的状態の変化が 喉頭と前喉頭関節が変化することもありうる。 Erickson et al. [2003a, b, 2004a-c] による予備調査では、演技音声と自発的で表情豊かな音声は舌や顎の明瞭度が異なるパターンを持ち、発声されていることを示した。 Schroeder et al. [1998] では、面白がる音声の聴覚-視覚的特性の調査を行い、 被験者が模倣された感情(驚きの表情)と本物の感情を区別して知覚できることを発見している。
発話者に同時に発話を行うことを強制する、例えば’泣く’といった発話者による特定の種類の強い感情表現は 感情と発話の間の可能な生理的な接続を考えるための窓口が開くため、 どの程度の感情と音声は関連をしており、どの程度に強い感情は、言語的タスクを妨害または高めることができるのかという研究をすることは 知覚と発話の情報の観点から 面白いものである。
Sad Speech¶
Scherer [1979] によると,悲しみ音声には最低でも2つの種類が存在する.
- 悲しい, 物静かな, 受動的音声
- 喪中を経験するようなタイプのアクティブな音声
前者はパラ言語情報として分類しなくても良いかもしれない. 後者は明確な非言語的感情の例である. 感情同期的な喚起は涙のような生理的変化に関連付けられている. アクティブな悲しみの感情はおそらく声帯振動パターンの制御に関与する運動協調だけでなく、声門上部の調音運動に影響を与える.
悲しく,物静かな音声の音響的特徴も多くの研究が存在する. それは F0 の値は低く[e.g., Iida, 2000; Eldred and Price, 1958], 低強度の音声で[e.g.,Eldred and Price, 1958], 持続時間が長い[e.g., Iida, 2000; Eldred and Price, 1958], スペクトルエネルギーの分布が変化するような声質の変化がある[e.g., Schereret al., 1991] 気息性の増加したものである.
増加した気息性は声帯振幅の開き方と関連があり, 高い声帯の振幅比(AQ)を反映し[Mokhtari and Campbell, 2002], 振幅の増加は第一倍音と他の倍音に関連し[e.g., Hanson et al., 2001], スペクトル傾斜にも同様の関連が見られる[e.g., Childers and Lee, 1991].
この種類の感情情報の収録が困難であることが原因であると思われるが 動的な悲嘆,喪しつを含む悲しみの種類の音響的特徴はあまり研究が進んでいない. しかし,ロシア語の嘆き音声の音響的研究が Mazo et al. [1995] 嘆きはいくつかのロシアの村で 悲しみを表現する際に使用される種類の情報であり, 定期的な歌、すすり泣き、興奮,叫び声、音声中断、ため息,加えて、呼吸を表す. 音響的な特徴として高い F0 をもち, 持続時間が変化とし1500 - 4500 Hz の間でエネルギーが増加し, ボーカルフライや二重音声のような声帯のゆらぎがあり, 振幅/周波数が同時に変調する.
非言語的感情情報の調音構造はすべてということならば、まだ調査されていない。 パラ言語情報の調音構造はそれなりに検討されている。 例えば、アメリカ英語では苛立ちの際、顎が低くなる [Menezes, 2003; Mitchell et al., 2000; Erickson et al., 1998] とか、 アメリカ英語[Ericksonet al., 2000], 日本語[Maekawa et al., 1999] の両方で疑わしいときに、舌背が前方に来て、称賛の際には後方にくる。 舌背の位置に対する音響的結果として疑いの際にF1とF2の双方を持ち上げ, 感嘆や、失望のときには引き下げる[e.g., Maekawaet al., 1999].
ここで我々の目的は自発感情に対する音響的、調音構造的特徴を調査することである。 今までの研究に対し [an extension of earlier work by Erickson et al.,2003a,b and 2004a-c] 人間が強く一般的な感情を表現している収録音声の調音指標(EMA)を比較することは革新的なアプローチである。 それぞれの話者は同じ語を発話し、自発的悲しみ音声の音響的、調音的特徴の比較を以下の2-3 個の条件で行った。
- 自発感情
- 感情模倣
- フレージング/イントネーションの模倣
- 読み上げ音声
悲しみ音声を使用した理由はこれが強い感情であり、発話者が収録時にその経験が豊かであったためである。 特に、我われは音響的特徴量として F0, フォルマント、 持続時間、 声質を調査した。 一方、調音構造としては、唇、舌、顎の位置を調べた。
我々は以下の条件を尋ねた。
- 同じ言語内容の読み上げ音声の比較において発音声の表現の特徴が何か
- 自発音声と、模倣音声の音響的、調音的特徴のどこに違いが存在するのか
‘模倣された’ 悲しみは ‘演技した’ 悲しみに似ているが、 模倣した悲しみにおいては、発話者に、自発音声の記録を聞きながら、できるだけ正確に自発音声の感情的発話運動を真似るように依頼している。 模倣音声の先行研究 [Erickson et al., 1990] では 発話者は声質ではなく、例えば、自発音声に於ける彼等独自の F0 のパターンを真似できることを示した。 感情模倣の誘発は発話者は敏感な特徴を評定する方法である。 しかし実際には自発発話の音響信号に現れているものとは異なる可能性もある。 したがって、このアプローチは、感情的音声の音響的特徴のいくつかを確認するための代替方法を提供します。 技演音声は恐らく、特定の感情を伝達するための人間のレパートリーをステレオタイプに表現したものである。 これは、感情模倣音声とも自発的感情音声とも異なるかもしれない。
A third question (3) we ask is whether there are acoustic and articulatory differences when the speaker imitates the spontaneous sad utterance vs. when she imitatesonly the phrasing and intonational patterns of the spontaneous sad utterance. Also, we ask (4) what are the acoustic and articulatory characteristics of speech that israted by listeners as very sad? Is this the same or different from spontaneous sad speech?In addition, we ask (5) whether there are common characteristics in the productionof emotional speech across different languages, e.g., American English and Japanese.On one hand, we might expect similarities because human beings experience basicemotions; however, we also would expect differences because of the complex interplaybetween the experience of emotion and the socio-linguistic constraints on the expres-sion of emotion.
A sixth question we ask is (6) what are the similarities/differences between per-ception of sad speech in diverse languages, such as American English and Japanese? Do listeners of different languages pay attention to different acoustic characteristics inperceiving whether an utterance is sad or not? The strengths of the study lie particularly in the joint acoustic and articulatorytreatment of the speech data and in the comparison of spontaneous and imitated emo-tion together with prosodic imitation without emotional expression. This type of studyhas not been done previously and as such, is a pioneering piece of work, presented hereas a pilot study, or ‘proof of method’. The weaknesses are those inherent in the non-laboratory design of the experiment: the linguistic content in terms of words/vowelsanalyzed is not strictly controlled nor is the timing of the collection of the spontaneousemotion for the speakers exactly the same, nor is the language - one speaker isAmerican, one is Japanese, albeit both are female speakers. We acknowledge the tentative nature of the results, which we hope can be used as a baseline or extension for fur-ther, more extensive work.
Methods¶
Data Recording¶
2D EMAシステムを使い, アメリカ人女性(中西部方言)と日本女性(広島方言)の音響及び調音データを収録した。 この研究の主な目的は自発感情音声 の解析収録の方法を確立することにあるため、二人の話し手の条件は厳密には同じものではない。 表 1 に様々な実験的差分を、発話者、言語、データセット、セッション、セッションのタイミング、発話、条件、対象となった母音、および、調音/音響指標 の観点から 要約している。
| Speaker/language | Sets of data | Sessions | Sessiontiming | Conditions | Word/vowel | Articulatory | Acousticmeasuresmeasures |
|---|---|---|---|---|---|---|---|
| American English | 2 sets
|
2 | 1 month prior to mother’s death (on day emotion, of operation imitated read for pancreatic emotion, imitatedcancer) and intonation, informal, 5 months later | 4 conditions: spontaneous emotion, imitated emotion, imitated intonation, | leave /i/ (2 utterances) | Jx, Jy, ULx, ULy, LLx, LLy, T1x, T1y, T2x, T2y, T3x, T3y | duration, F0, F1, F2 and amplitude of glottal opening(AQ)s |
| Japanese | 2 sets
|
1 | 4 months after mother’s sudden deat due to brain aneurysm | 3 conditions: spontaneous emotion, imitated emotion, read | kara /a/ (2 utterances) | Jx, Jy, ULx, ULy,LLx, LLy, T1x, T1y, | duration, F0, F1, F2, and spectral tilt |
それぞれの発話者毎に、二つのデータセットを収録した。 セット1 他の発話者との 気楽な自発電話音声 を収録したものであり、イヤフォンとマイクロフォン を通した音声である。 発話相手は別の部屋に座っている。 アメリカ人の場合、もう一人の発話者は第三者(友人/同僚)である。 日本人の場合、発話相手は六人いる。 発話相手には被験者の私生活に関連した話題のリストに基づいて、幸福感や悲しさ、又は怒りを呼び起こすような様々な質問をリハーサルなしで行うように依頼した。 悲しんでいる感情(発話中嗚咽することを含む)を収集するための 実験のタイミングは幸運にもアメリカ人の場合、被験者の母親が丁度致命的な病気であると診断されたことを知ったタイミングであった。 また、日本人のケースにおいては、被験者は母親を脳動脈瘤のため最近失ったばかりであった。 対話相手は最近おきた悲しむべき状況に気が付き、インタビューの多くはこのことが中心に行われた。 EMA 収録はフレーム間の約 3s を ブレイクとする 20 s のウインドウ幅で行い、 対話は自然な方法に留まっていた。 音響収録は行った。 ビデオ収録も行っているが本文での解析には使用していない。
セット2 の発話は最初のデータ収録用の制御データである。 これは発話中発話者が泣いてしまうことがあったため, 制御実験のため特定の発話が選択された。 しかし、表1 に示した通り、アメリカ人英語話者に対しては収録が5ヶ月後に行われている。 一方、日本人に対しては被験者が異る実験的プロトコルの文章のリストを読み上げたあと収録は同じセッションの一時間後に行われている . 二つのセッションは感情発話から得られる最もよい制御データを選択するさい、十分な時間を用意する際に有利であった。 しかし、 調音指標をえるための EMA を調整で、二つのセッション間で5度の差がある点は不利である。 一つのセッションを他のセッションの座標と数学的にデータ形式を変更することでマッチさせることはデータ選択に掛かる時間の大きさから断念をした。 今後の課題としてこの手の制御条件から分けられたセッションで自発感情音声を収集することが推奨される。
両方の話し手は表1に示された方法に従ってオリジナルの発話を行うように依頼された。 アメリカ人に対しては4つの条件が存在するのに対し、日本人に対しては3 つの条件しか存在しないことに注意して欲しい。 この理由は以下のアイテム 2 で説明を行う。
Control Condition 1 (Imitated Emotion).¶
シャドウイングのように、 テープに録音されたオリジナル発話を ヘッドフォンを通して聞いたり, 台本をみたりして、(アメリカ人の場合オリジナル発話のイントネーションパターンとフレージングにマークがされている) 単語、フレーズ、イントネーション、感情を模倣した。 感情模倣発話(IE) はアメリカ人で 3 回、日本人で6回繰り返した。 解析の目的上、最初に三回繰り返された単語のみを調査した。 発話は20秒ほど長くなったが、発話者は模倣発話の間にテキストのコピーを見て行たためである。
Control Condition 2 (Imitated Intonation).¶
アメリカ人話者にのみ、単語のみ、フレーズのみ、イントネーション(感情をふくまない)のみの模倣(シャドウイングなど)を 台本を見たり、オリジナルの音源を聞いたりするときに行った。 イントネーション模倣発話(II)は三回繰り返した。 アメリカ人話者は音韻論の訓練を受けており、この課題を容易にこなすことができた。 しかし、日本人の場合、セッションは一回のみであり、発話者にコーチをする時間もなかったため容易ではなかった。
Control Condition 3 (Read).¶
音声書き起し文章によるオリジナル発話の読み上げも行った。 日本人の場合、書き起し文章は日本語のライティングシステムを使用している。 読み上げ発話(R)はアメリカ英語では二回、日本人話者では六回行った。 最初の三回の繰り返し音声の語のみを解析の対象としている。
Utterances¶
理想的には、我々は二つの言語を通し、同じ母音文脈を維持したい。 しかし、leave という語と かな(だからの意)を選択した。 これは両被験者が最もつよく悲しみの感情を示した語が存在したからである。 また、これ以外に同様の母音文脈で強い悲しみを示した例は存在しなかった。
アメリカ英語の悲しみ音声に関して、我われは、leave という語の例を解析した。 これは20 秒の発話中、単一発話が二回発話されており、発話全体では 4 回未満であった。
- 発話者が母を亡くした時の最初の実験における発話(i.e., actually sobbing);
- (IE) オリジナルの発話の音声収録を聞きながらのフレーズ、イントネーション, 感情の模倣
- オリジナル発話の音声収録を聞きながらのフレーズとイントネーションのみの模倣
- オリジナル発話と同じ、フレーズ、イントネーションを保持した読み上げ音声
E 発話 * 2, IE 発話 * 6, II 発話 * 6, R 発話 * 2 の合計で、 16 個の収録が存在する。
日本語悲しみ発話では、 E (発話者の ‘かな’ を発話したさい、 cheek1 では涙を流している), IE, R の 3 つの発話条件のもとで 二回発話起きた “から” という語を解析の対象にしている。 E 発話で 2 回, IE 発話で 6 回, R 発話で 6 回の合計、14 回, ‘かな’ という収録があった。
Articulatory Analysis Method¶
We examined the movement of the EMA receiver coils attached to the (1) lower incisor(mandible) (2) upper lip, (3) lower lip, and (4) receiver coils (T1, T2, T3, T4) attached along the longi-tudinal sulcus of the speaker’s tongue. The positions of the transmitter coils determine thecoordinate system [Kaburagi and Honda, 1997] with the origin positioned slightly in front of and belowthe chin. All EMA values are positive, with increasingly positive y-values indicating increasingly raisedjaw or tongue position, and increasingly positive x-values, increasingly retracted jaw or tongue position.The coordinates of the American English speaker’s first recording were transformed by 5 degrees,which was the measured difference between the coordinates in the two sessions [Erickson et al., 2003b].
Articulatory measurements were made for the x-y coil positions for the upper and lower lip (UL,LL), for the mandible (J), and the tongue (T1, T2, T3, T4) at the time of maximum jaw opening for theutterance, using a MATLAB-based analysis program. Note that T4 recordings were not reliable foreither of the speakers, and T3 was not reliable for the Japanese speaker because of coil-tracking prob-lems. For the American English utterances, articulatory as well as acoustic measurements were madeat the time of maximum jaw opening for leave. For the Japanese utterances, articulatory measure-ments were made at the time of maximum jaw opening during the second mora in the utterance kara.
- As seen from the video images, for the Japanese speaker, the manifestation of crying was tears running down thecheeks; for the American speaker, the face was contorted in a sobbing posture with jaw open and eyebrows knittogether, as well as tears.
A sample of a data file is shown for Japanese in figure 1. Notice there are two distinct jaw openings,one for each mora. However, for two of the utterances (one IE and one R), there was only one jawopening, which occurred at the plosion release for /k/.
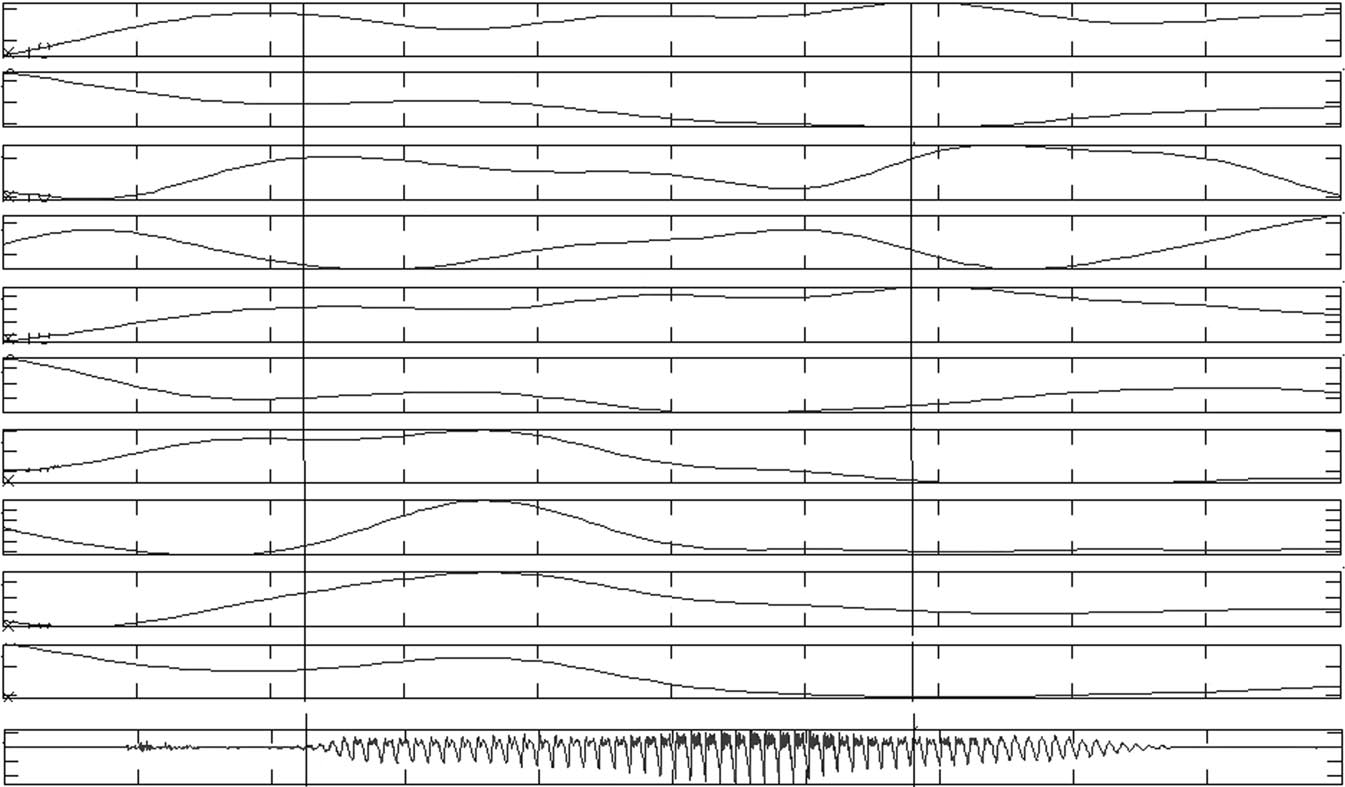
Fig. 1. Sample articulatory data of kara from utterance 81 (E). The bottom trace is the acoustic wave-form. Vertical lines indicate lowest Jy position in each mora. Articulatory measurements made duringthe second mora were used in the analysis. The x-axis shows time in seconds. The values of the tickmarkings for the y-axes are as follows: Jx 7.85-7.80 mm; Jy 12.8-12.6 mm; ULx 5.9-5.85 mm; ULy15.2-15.15 mm; LLx 6.45-6.3 mm; LLy 13.6-13.3 mm; T1x 9.2-8.8 mm; T1y 14.8-14.0 mm; T2x10.2-9.8 mm; T2y 20-14.5 mm.
Acoustic Analysis Method¶
アメリカ英語及び、日本語データの双方で 我われは、持続時間、F0, F1, 及び声質の計測を行った。 アメリカ英語に関しては、Parham Mokhtari との先行する共同研究[see Ericksonet al., 2003b] から, 以下に記述するように、声帯信号の生成物から推定した声帯閉鎖の AQ を調査することができた。 しかし、日本語の解析に関してはこの手法でアクセスすることができなかったため、 我われは以下に記述するように、スペクトル傾斜を調査する単純な手法を使用した.
American English.¶
単語レベルでの響的音解析(持続時間, F0, F1, 声帯閉鎖) を逆フィルター法と発話様式推定法を使って行った。 これは Mokhtari and Campbell [2003] を参考にしている.
われわれの研究では、F0, F1, AQ の結果に注目した。 具体的には EMA の結果から特定した、シラブル核のうち最も顎が開いた時のの時間を観察している。
Broad and Clermont [1986] で提案されたケプストラムからフォルマントへの線形マッピング法を使用し 最初の4フォルマントフリークエンシーとバンド帯域の最初の予測結果を使用して, 線形予測ケプストラムを計測した。 Although the mapping had been trained on a subsetof carefully measured formants of a female speaker of Japanese [Mokhtari et al., 2001], it was foundto yield remarkably reasonable results for the American female speaker, as judged by visual inspectionof the formant estimates superimposed on spectrograms. These formant estimates were then refined ateach frame independently, by an automatic method of analysis-by-resynthesis whereby all 8 para-meters (4 formant frequencies and bandwidths) are iteratively adjusted in order to minimize a distance between a formant-generated (or simplified) spectrum and the original FFT spectrum of the sameanalysis frame. The optimized formants centered around the point of maximum jaw opening in eachutterance of leave were then used to construct time-varying inverse filters with the aim of eliminatingthe effects of the vocal-tract resonances (or formants). The speech signal was first high-pass filtered toeliminate low-frequency rumble (below 70 Hz), then low-pass filtered to eliminate information abovethe fourth formant, and finally inverse filtered to eliminate the effect of the first 4 vocal-tract resonances. The resulting signal (52 ms) was integrated to obtain an estimate of the glottal flow waveform.
The glottal AQ, proposed independently by Fant et al. [1994] and Alku and Vilkman [1996] isdefined as the peak-to-peak amplitude of the estimated glottal flow waveform divided by the amplitudeof the minimum of the derivative of the estimated flow. It is a relatively robust, amplitude-based meas-ure which gives an indication of the effective duration of the closing phase of the glottal cycle. As dis-cussed by Alku et al. [2002], AQ quantifies the type of phonation which is auditorily perceived alongthe continuum from a more pressed (i.e., creaky) to a more breathy voice quality.
Japanese.¶
Acoustic analyses of the /ra/ mora - duration, spectral tilt, F0, and F1 (around the mid-portion of the /ra/ mora in kara) - were done using Kay Multispeech 3700 Workstation. We tried ordi-nary methods to characterize the creakiness of the voices, e.g., comparison of H1 with H2 or H3 [NíChasaide and Gobl, 1997]. However, because of the irregular glottal pulsing in nonmodal phonation anextra set of harmonics appear parallel to F0 and its harmonics [Gerratt and Kreiman, 2001], and it wasnot easy to reliably resolve each harmonic. However, visual inspection of the FFT results reveals thatspectral differences of the three categories of speech reside in the strength of the energy around F1, i.e.,600-1,000 Hz, with R having the strongest energy and IE, the weakest. Therefore we devised a methodto capture the gross characteristics of the harmonics. A regression analysis was made for each FFTresult (512 points) from H1 to 1,000 Hz, with the slope of the regression line taken as an index of spec-tral tilt. Fitting a single regression line to spectrum was explored in Jackson et al. [1985].
Perceptual Analysis¶
The words used in the acoustic/articulatory analyses (described in ‘Utterances’ above) were pre-sented for auditory judgment in randomized order 4 times with HDA200 Sennheiser headphones in aquiet room, using a G3-Macintosh computer and Psyscope software. The task was to rate each wordaccording to the perceived degree of sadness (5-point scale; 5, saddest). A practice test of 6 utterancespreceded the test. For the American English test, the 16 instances of leave were presented auditorily to11 American college students (4 males, 7 females) at The Ohio State University; for the Japanese test,the 14 instances of kara were presented auditorily to 10 Japanese female college students at Gifu CityWomen’s College.
Results¶
Perception Test Results¶
For both American English and Japanese, listeners ranked emotional and imitatedemotional speech as sadder than read speech, and in the case of American English,emotional and imitated emotional speech as sadder than imitated intonation speech, ascan be seen in figure 2.
One-way ANOVA of the perceptual ratings (mean for all the listeners) with theutterance conditions (4 levels: E, IE, II, R for American English and 3 levels: E, IE, R forJapanese) as an explanatory variable found significant main effects for both languages(American English, F(3,12) = 351.328, p < 0.000; Japanese, F(2,11) = 14.704,p < 0.001). The Bonferroni pairwise comparisons revealed that perceptual rating ofsadness is significantly higher for E and IE compared to II and R for American English(p < 0.000), and for IE compared to R for Japanese (p = 0.001). The finding that imitated intonation in American English was not rated as sad as spontaneous or imitated various studies about the multicomplex richness of expressive speech, see e.g.,Schroeder [2004], Gobl and Ní Chasaide [2003] and Douglas-Cowie et al. [2003].
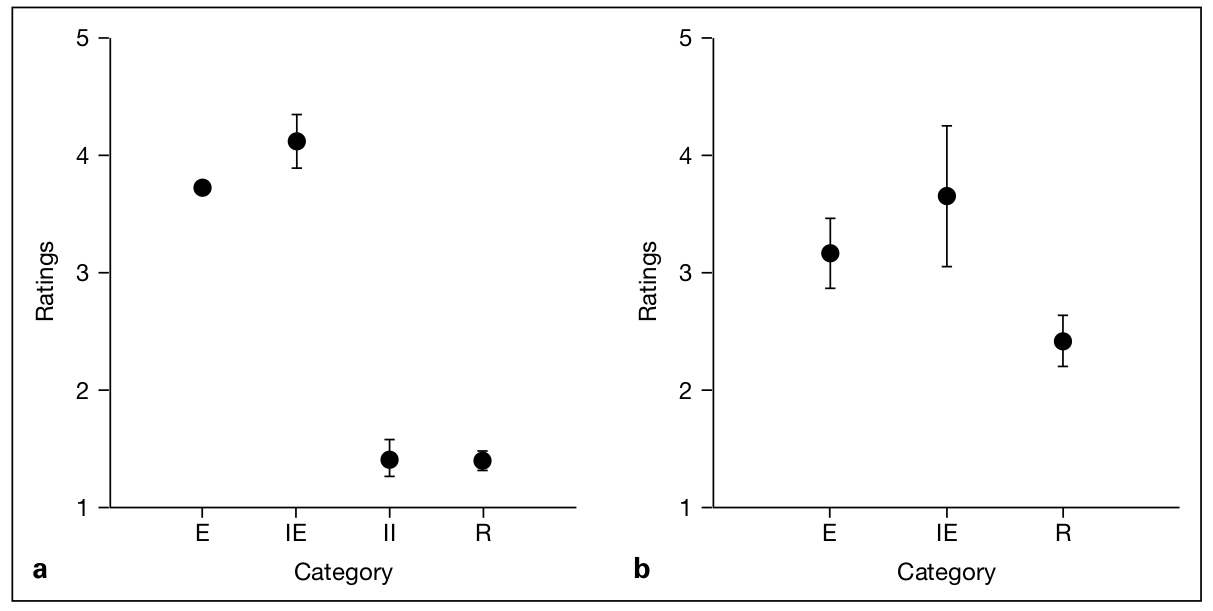
Fig. 2. Ratings by American listeners of the perceived degree of sadness of 16 utterances of leave(left side) and ratings by Japanese listeners of perceived degree of sadness of 14 utterances of kara(right side). The error bars indicate standard deviation of p = 0.68.
Imitated expressions of sadness (IE) were actually rated as slightly sadder thanspontaneous expressions of sadness (E) for both American English and Japanese.However, the differences were not significant. A larger sample size is necessary to fur-ther explore this.
Acoustic Analysis Results¶
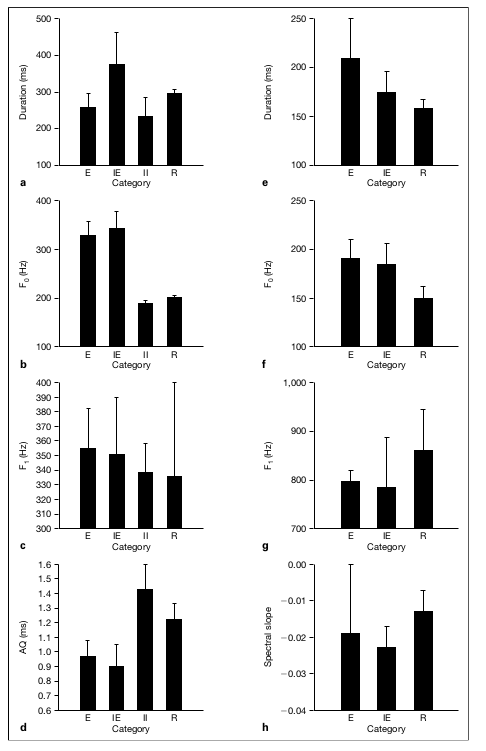
Fig.3. Results of acoustic measurements, both for American English leave (left side) and Japanese kara (right side) for each of the utterance conditions. From top to bottom, duration, F0, F1, AQ (for American English) and spectral slope (for Japanese). The error bars indicate standard deviation of p = 0.68.
Figure 3 shows the results of the acoustic analysis of American English and Japanese speech. The averaged acoustic values are shown in tables 1A and 2A in the Appendix.
Figure 3 shows that F0, F1 and voice quality (but not duration) of imitated sadspeech are similar to those for spontaneous sad speech. One-way ANOVA of theacoustic measures (F0, F1, voice quality, and duration) with the utterance conditions (E,IE, II, R for American English and E, IE, R for Japanese) as an explanatory variablefound main effects for duration, F0 and AQ for American English and for duration andF0 for Japanese (table 3A in the Appendix). Bonferroni pairwise comparisons found nosignificant differences between the E and IE conditions for F0, duration and voice quality for either the American English or Japanese. Both speakers showed a higher F0 forsad and imitated sad speech than for read speech (and imitated intonation speech). Bonferroni pairwise comparisons found F0 was significantly higher for E and IE com-pared to II and R for American English (p < 0.000), and for E and IE compared to R(p = 0.013 and p = 0.038, respectively) for Japanese. The finding of high F0 (whichwas clearly audible) is different from that usually reported for sad quiet speech, butsimilar to what was found for the active grieving seen in Russian laments.
F1 values were similar for spontaneous and imitated sad compared to those for read(and imitated intonation) speech: for the American English speaker (for the vowel /i/), sadness suggests that intonation itself is not sufficient to convey sadness; as discussed in’Results of Pearson Correlation with Ratings of Sadness and Accoustic/ArticulatoryMeasures’ below, voice quality and F0 height are salient characteristics of sadness.
F1 values for sad and imitated sad speech were higher, and for the Japanese speaker(for the vowel /a/), they were lower. These differences were not significant. However,the graphs suggest a tendency for the /i/ and /a/ vowels to centralize in sad speech; thisneeds further investigation. The finding of low F1 for sad and imitated sad utterancesfor the Japanese speaker is reminiscent of the finding of lowered F1 values for disap-pointment (also for the vowel /a/) reported by Maekawa et al. [1999].
In addition, both speakers showed changes in voice quality for the sad and imi-tated sad speech, compared with the read (and imitated intonation) speech. For theAmerican English speaker, both spontaneous and imitated sad speech have a low AQ.Bonferroni pairwise comparisons found AQ significantly lower for E and IE comparedto II (E < II: p = 0.018; IE < II: p < 0.000), and for the Japanese speaker, a steepspectral tilt (but no significant differences).
The finding of low AQ for the American English spontaneous sad utterances is dif-ferent from the high AQ previously reported for sad, quiet breathy speech. It may be thatlow AQ is seen in active grieving because crying would probably involve muscular ten-sion, including tension of the vocal folds. When vocal folds are tense/pressed, the dura-tion of vocal fold closure is large, and this would lower AQ.

Fig. 4. Sample acoustic wave forms for Japanese kara. The top panel is sad speech (E), next is imitatedsad speech (IE), and the bottom is read (R) speech. Each tick marking on the time axis indicates 100 ms.
As for the Japanese, spontaneous sad speech was perceived by the authors to bebreathy-voiced and the imitated sad, creaky-voiced, and this can be seen in the acousticwaveforms in figure 4. The spontaneous sad speech in the top panel of the figure shows relatively smooth phonation for breathy voice [similar to that shown for breathy voice by Ishii, 2004]; the imitated sad speech in the middle panel shows irregular and sporadic phonation, typical of creaky voice [see also, e.g., Ishii, 2004, as well as e.g., Redi and Shattuck-Hufnagel, 2001], and the read speech in the bottom panel shows regular pulsing with clear vowel-formant characteristics, though some creakiness towards the end.
A comment about spectral tilt and breathiness/creaky voice: That breathy utterances have steep spectral slopes is relatively well known [e.g., Klatt and Klatt, 1990; Johnson, 2003], as is also that sad utterances tend to be breathy [i.e., Mohktari and Campbell, 2002]. Creaky utterances at low F 0 are not characterized by steep spectral tilt [e.g., Klatt and Klatt, 1990; Johnson, 2003]. However, in the Japanese data we obtained, we see a steep spectral tilt associated with the creaky voice of the imitated sadness. It may be that depending on the value of F 0 , the spectral slope of the creaky utterances changes, so that at high F 0 , creaky utterances have very steep spectral slopes. As Gerratt and Kreiman [2001] argue, characterization of variation in nonmodal phonation is not straightforward due to complications of both taxonomy and methods. Phonetic characterization of voice quality changes associated with emotions in speech has not yet been done; however, see e.g., Gobl and Ní Chasaide [2003] for their summary of voice quality analysis of expressive speech.
The averaged durations of the imitated sad speech for the American Englishspeaker were generally longer than those of the spontaneous sad speech, as well as theother conditions. However, the only significant difference was for IE compared to II(p = 0.007). Perhaps the reason the imitated sad speech was longer than the sponta-neous sad speech was because the speaker was expecting sad speech to be slow, andmay have inadvertently allowed this expectation to influence her production.
For the Japanese speaker, the spontaneous and imitated sad utterances tended to belonger than the read utterances and significantly longer for E compared to R(p = 0.023), which is consistent with what is reported in the literature for sad speech.
Articulatory Analysis Results¶
Figure 5 shows the averaged horizontal and vertical coil positions for theAmerican English and Japanese speakers. Whereas the acoustic characteristics of spon-taneous and imitated sadness were fairly similar, the articulatory characteristics ofthese two conditions are different: imitated sad speech tends to be similar to readspeech, or imitated intonation, rather than to spontaneous sadness. The averaged artic-ulatory values are shown in tables 4A and 5A in the Appendix. Table 2 summarizes thesignificantly different characteristics (p < 0.05 based on Bonferroni pairwise compar-isons) between sad and imitated sad speech.
| Upper lip | Lower lip | Jaw | Tongue tip | Tongue blade | Tongue dorsum |
|---|---|---|---|---|---|
| Spontaneous sad speech | retracted for Am. Eng.
|
retracted, lowered for Am.Eng.
|
fronted for Am. Eng.
|
fronted for Am.Eng | fronted, raised for Am.Eng. |
| Imitated sadspeech | protrudedfor Am. Eng.
|
protruded, raised for Am.Eng.
|
backed for Am.Eng.
|
backed for Am. Eng | backed, lowered for Am. Eng |
For the American English speaker for spontaneous sadness compared with theother conditions (fig. 5 left side), the upper lip and lower lip are retracted, the lower lipis raised, the jaw is lowered, the tongue tip is fronted, the tongue blade is fronted andthe tongue dorsum is fronted and raised. One-way ANOVA of the articulatory measures (UL, LL, J, T1, T2 and T3) with the utterance conditions (E, IE, II, R) as factors foundsignificant main effects (table 6A in the Appendix). Bonferroni pairwise comparisonsfound ULx more retracted for E compared to IE, II, and R (p < 0.000), LLx moreretracted for E compared to IE, II (p < 0.000), and R (p = 0.031), LLy more raised forE compared with IE, II, and R (p < 0.01), Jx more retracted for E compared to IE(p = 0.005) (while IE is more protruded than II, p = 0.004 or R, p < 0.000), Jy lowerfor E compared to IE (p = 0.018), T1x more fronted for E compared to IE, II and R(p < 0.000), T1y lower for E compared to II (p = 0.025), T2x more fronted for E com-pared to IE and II (p < 0.000) and R (p = 0.002), T3x more fronted for E compared toIE, II and R (p < 0.000) and T3y for E more raised compared to IE, II, and R(p < 0.000).
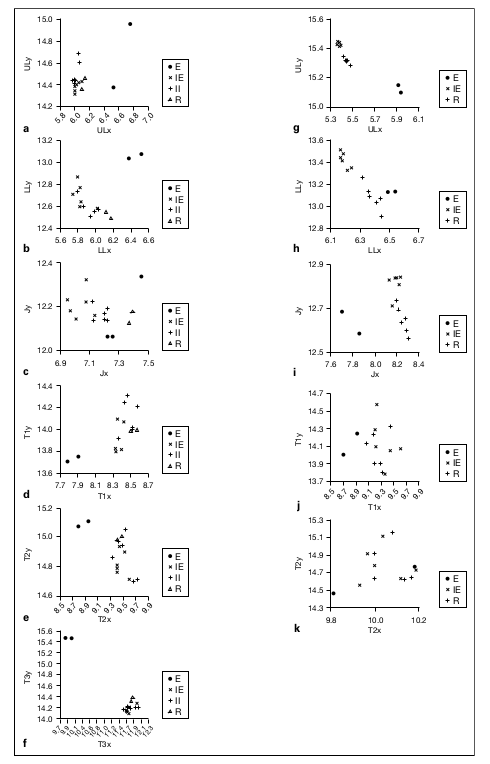
Fig. 5. Results of articulatory x-y measurements in millimeters for UL, LL, J and T1, T2, and T3.American English leave is on left-side, and Japanese kara is on right side. Smallest y-axis values indi-cate lowest coil positions, and smallest x-axis values indicate most forward coil positions, so that thelower left corner of the graphs indicate the lowest, most forward position of the articulators (as if thespeaker were facing to the left of the page). E indicates sad speech, IE, imitated sad speech, II, imi-tated intonational speech, and R, read speech.
That the American English speaker showed tongue blade/dorsum raising andfronting for sad speech may be associated with the more open jaw used by this speaker,and the necessity to produce a phonologically recognizable high /i/ vowel when the jawis open [see e.g., Erickson, 2002].
For the Japanese speaker for sad speech compared to the other conditions (fig. 5right side), the upper and lower lips are retracted and lowered, the jaw is protruded andlowered (but lowered only compared with imitated sad speech, not read speech), andthe tongue tip is fronted. One-way ANOVA of the articulatory measures (UL, LL, J, T1,T2 and T3) with the utterance conditions (E, IE, R) as factors found significant maineffects (table 6A in the Appendix). Bonferroni pairwise comparisons found ULx moreretracted for E compared to IE and R (p < 0.000), ULy lower for E compared to IE andR (p < 0.000), LLx more retracted for E compared to IE (p < 0.000) and R (p = 0.009),LLy lower for E compared with IE (p = 0.009), Jx more protruded for E compared toIE and R (p < 0.000) and Jy lower for E compared to IE (p = 0.010), and T1x morefronted for E compared to IE (p = 0.003) and R (p = 0.012).
It is interesting that in imitating sadness, both speakers showed protruded lips,configuring a lip-pouting position. It is also interesting that this gesture is differentfrom the one used for spontaneous sad speech, in which both speakers retracted theirlips. It may be that sadness with strong crying is likely to produce lip retractionwhereas imitated sadness without crying need not.
Another interesting characteristic of sad speech by the American English speakerwas the raised upper (for one of the utterances) and lower lips (see second graph leftside of fig. 5), which matches Darwin’s [1872, pp. 162-164] description of the typicalsquare-shaped open-mouth crying face. According to Darwin, crying is initiated byknitting the eyebrows together. This maneuvre supposedly is necessary in order to pro-tect the eye during violent expiration in order to limit the dilation of the blood vessels[p.162]. Contraction of the orbicular muscles causes the upper lip to be pulled up, andif the mouth is open, then the result is the characteristic square-shaped mouth of crying.The video image of the American English speaker while crying and saying the word’leave’ was exactly this. The raised upper and lower lips follow from the knitted eye-brows of this speaker when crying. Results of Pearson Correlation with Ratings of Sadness andAcoustic/Articulatory MeasuresScatter plots of sadness ratings as a function of F0, voice quality (AQ for Americanand spectral slope for Japanese), F1, and duration are shown in figure 6. High ratings ofsadness are associated with high F0 (both American English and Japanese) low F1 (onlyfor Japanese), and steep spectral slope (only for Japanese), high AQ (for AmericanEnglish), and increased duration (only for American English). A Pearson correlationanalysis for Japanese (using the numerical results listed in tables 2A and 5A) showed asignificant linear correlation (p < 0.01) between sadness judgments and F0 (r = 0.81),spectral slope (r = ⫺0.69) and F1 (r = ⫺0.68); however, for American English raters,no Pearson correlation could be done since there was a bimodal distribution. It is notclear why the American English speaker showed a bimodal distribution. The smallsample size may have contributed to the bimodal patterns. Figure 7 shows sadness ratings and articulatory measures (LLy, T1y, and Jx for various studies about the multicomplex richness of expressive speech, see e.g.,Schroeder [2004], Gobl and Ní Chasaide [2003] and Douglas-Cowie et al. [2003]. American English, and LLy, LLx, and Jy for Japanese). Japanese listeners displayed a significant linear correlation between ratings ofsadness and raised lower lip (r = 0.76, p < 0.01), whereas American listeners showeda bimodal distribution, with low sadness ratings associated with lowered lower lip,raised tongue tip, and retracted jaw, and high sadness ratings associated with raisedlower lip, lowered tongue tip and protruded jaw, which also may be related to thisspeaker’s bimodal production of F0 values. A potential relation between supraglottalarticulation and laryngeal tension is discussed at the end of this section. For Japanese,sadness judgments showed a significant correlation (p < 0.01) with protruded lowerlip (r = ⫺0.65) and raised jaw (r = 0.76). Table 3 summarizes the pertinent acoustic and articulatory characteristics of well-perceived sad speech. The articulatory and acoustic characteristics of well-perceivedsad American English speech are included here, since it is not clear whether the patternof bimodal distribution is an artifact of the lack of a continuous range of F0 valuesand/or small sample size. We interpret the results of the correlation between listener ratings of sadness andacoustic/articulatory measures as follows. In imitating sad speech, the AmericanEnglish and the Japanese speaker successfully imitated the high F0 and changed voicequality characteristics of the spontaneous sad speech. However, it seems that there is a difference between the way a speaker articulatesspontaneous sad speech, and what articulatory characteristics ‘convey’ sadness to a lis-tener. For both American English and Japanese, speech that was given a high rating for various studies about the multicomplex richness of expressive speech, see e.g.,Schroeder [2004], Gobl and Ní Chasaide [2003] and Douglas-Cowie et al. [2003].

Fig. 6. Scatter plots of acoustic measurements and perception ratings for American English (leftside) and Japanese (right side). E indicates sad speech, IE, imitated sad speech, II, imitated intona-tional speech, and R, read speech.

Fig. 7. Scatter plots of articulatory measurements and perception ratings for American English (leftside) and Japanese (right side). E indicates sad speech, IE, imitated sad speech, II, imitated intonationalspeech, and R, read speech. For the vertical coil positions, the lowest value indicates lowest coil position;for the horizontal coil positions, the lowest value indicates the more forward (advanced) coil position.
| Well-perceived sad speech | Lower lip | Jaw | Tongue tip | F0 | F1 | Dur. | Voice quality |
|---|---|---|---|---|---|---|---|
| American English | raised | protruded | lowered | raised | long | low AQ | |
| Japanese | raised, protruded | raised | raised | lowered | sharp spectral slope |

Fig. 8. Scatter plots of acoustic/articulatory measurements and voice quality measurements forAmerican English (left side) and Japanese (right side). E indicates sad speech, IE, imitated sad speech,II, imitated intonational speech, and R, read speech.
| Voice quality | Lower lips | Jaw | Tongue tip | F0 |
|---|---|---|---|---|
| American English (low AQ) | lowered | raised | ||
| Japanese (sharp spectral slope) | raised | raised | raised |
We also examined correlations between voice quality and acoustic/articulatorymeasures as shown in figure 8. Table 4 summarizes the acoustic and articulatory char-acteristics associated with voice quality. For the Japanese speaker, there was a significant correlation (p < 0.01) betweenvoice quality and F0 (r = ⫺0.64), with spectral slope becoming steeper as F0 becomeshigher. There was also a significant correlation between spectral slope and lower LL-y(r = 0.61, p < 0.05), and Jy (r = ⫺0.63, p < 0.01) with spectral slope becomingsteeper as the jaw and lower lip were more raised. For the American English speaker, F0 appears to be negatively correlated with AQin the high F0 range (300 z and above), but not in the modal F0 range (around 200 Hz)which does not show any correlation. There could be a connection between cricothyroidactivity and AQ which could account for this distribution pattern. At normal F0, presum-ably when the cricothyroid is less active, this speaker tends to have a breathy voice withAQ greater than 1.0, but at high F0 when the vocal folds are more tense due to increasedcricothyroid activity, we see lower AQ values. The relationship between speaking ranges(high, modal, low) and AQ is an interesting topic for further investigation. In addition, there was a significant correlation between AQ and T1y (r = 0.64,p < 0.01). In the mid range of tongue tip height, the scatter plot shows no relationshipwith AQ; only at the extremes of tongue tip height do we see a correlation such that lowAQ is associated with low tongue tip and high AQ with high tongue tip. This needs tobe investigated further. The results suggest a relation for American English between low AQ and raised F0,as well as lowered tongue tip, and for Japanese, between steep spectral slope and raisedF0, raised jaw, lowered lip. Perhaps the maneuvers during imitated sadness of loweringthe tongue tip (in the case of American English) or raising of the lips (in the case ofJapanese) pull the larynx forward, change the vocal fold dynamics, and bring aboutirregular phonation, and in this way, contribute to either steepness of spectral slope orcreakiness of voice, and consequently, to the listener’s perception of sadness. Thishypothesis needs to be explored further.
Conclusion¶
本研究では音響/調音データを収録する複製可能で新しい自発感情音声の収録方法を報告した。 この研究にはいくつかの欠点が存在する。
発見は、二人の発話者の異なる母音核を持つ二つの発話タイプに基づいている。 ここには、いくつかの疑問が残る。 どのように、自発悲しみ音声を、演技悲しみ音声や読み上げ音声と比較をするのか. 本当にリスナーな強い悲しみを感じるのか。 どのように、自発悲しみ音声、模倣悲しみ音声を多言語間で横断的に比較をするのか(日本語と英語のように).
実験の性質は実験室のように実験デザインを制御できるものではないため、 このタイプの初期探索アプローチは、より良い音声における自発的な感情の話題を調査するために、研究を進める方法を知るために収録されたものである。
結果は、アメリカ英語と日本語双方において、悲しい音声が高い F0 を特徴としていることを示している。 また、F1 だけではなく、声質(例えば声門閉鎖サイクルの特徴/スペクトルチルトなど)も変化する傾向にあることを示している。
However, we see differences in terms of articulation. For the American speaker,the upper lip was retracted, the lower lip was retracted and raised while the jaw wasretracted and lowered, the tongue tip fronted and lowered, the tongue blade fronted,and the tongue dorsum fronted and raised for spontaneous sad speech; for imitated sadspeech, the upper and lower lips were protruded and lowered, the jaw was protrudedand raised, the tongue tip, backed and raised, the tongue blade backed and the tonguedorsum, backed and lowered. For the Japanese speaker, both upper and lower lips wereretracted and lowered, the jaw was protruded and lowered, and the tongue tip frontedfor spontaneous sad speech; for imitated sad speech both upper and lower lips wereprotruded and raised, the jaw was retracted and raised, and the tongue tip, backed. The results suggest that articulation of strong emotions by a speaker, such as cry-ing while at the same time forcing oneself to speak, is different from acted/imitatedemotion. Further exploration is needed into possible physiological connectionsbetween emotion and speech in terms of production and perception, as well as into bio-logical underpinnings of sad speech. Imitated sad speech showed a tendency (although no significant differences werefound) for even more changed voice quality characteristics, i.e., more change in glottalopening characteristics or steeper spectral tilt, which perhaps contributed to listeners ratingimitated sadness as more sad than spontaneous sadness. One reason for this may be thatfor imitated sadness, the speaker is trying to ‘convey’ sadness, but real sadness is the resultof the speaker’s internal state, something that the speaker does not control that happens inspite of the speaker’s intentions. That spontaneous sadness has a distinctly different patternof articulation involving the jaw and lips (and tongue for American English) may be not forthe purpose of conveying sadness, but be the by-product of experiencing sadness. The fact that both the Japanese and the American English speaker in imitating sad-ness, pouted lips for imitated sadness, i.e., the upper and lower lips were protruded, fur-thermore suggests there may be ‘universal’ postures for imitating sadness that are notnecessarily the same as those for producing spontaneous sadness. In acted emotion, thespeaker is volitionally changing the acoustic signal to impart to the listener a mental oremotional state (paralanguage) while in spontaneous emotion the speaker is working atmaintaining the acoustic signal to convey the intended message even through emotionalinterruptions (nonlanguage). From the results of this study, we see it is important toclearly identify what a researcher of emotion intends to study and to choose the righttesting paradigm. Using actors in emotion studies will give results on paralanguage andnot results on emotion as such. Therefore, to study emotional characteristics of speech(articulatory phonetics, etc.) researchers need to move away from using actors. An interesting result with imitated emotion is that the speakers seem to have beensensitive to imitating certain parts of their spontaneous sad speech, but not to others. Forinstance, the American English speaker (a phonetician) imitated F0, F1 and voice qualityof the sad speech rather successfully, but not duration. It was as if duration was’recalled’ from a set of stereotypes of what constitutes sad speech. A similar situation various studies about the multicomplex richness of expressive speech, see e.g.,Schroeder [2004], Gobl and Ní Chasaide [2003] and Douglas-Cowie et al. [2003].
With regard to imitated intonation (in which the American English speaker imitatedthe intonational and phrasing patterns, but not F0 range), imitated intonation speech is(a) different from spontaneous sad speech/imitated sad speech in terms of acoustics andarticulation, (b) not rated highly by listeners as sad, and (c) shows low correlation of itsacoustic characteristics with speech that was highly rated by listeners as sad. Theacoustic characteristic that correlated highly with listeners ratings of sadness were highF0 and low AQ (both characteristics of spontaneous sad or imitated sad speech, but notimitated intonation speech). These results suggest that intonation and phrasing patternsmay not be sufficient to convey emotional information to listeners, a finding which isreminiscent of that reported by Menezes [2004] who showed that phrasing patterns inthemselves were not salient characteristics of irritated utterances (vs. non-irritated utter-ances). More research needs to be done in this area in order to better understand the rela-tionship between intonation, phrasing, F0 range, and voice quality. With regard to the rating of sadness by listeners, we see a difference between the waya speaker articulates spontaneous sad speech and those articulatory characteristics which’convey’ sadness to a listener. For both American English and Japanese, speech that wasgiven a high rating for sadness by listeners, involved lip-pouting with raised and/or pro-truded jaw/lower lip. However, in actual articulation of spontaneous sad speech, we see theopposite: lowered and retracted jaw and retracted lower lip for American English and low-ered jaw and lowered retracted lower lip for Japanese. The pattern of articulation for well-perceived sad speech seems to be similar to that for imitated sad speech, rather thanspontaneous sad speech. This is a very interesting finding and needs to be explored further.With regard to whether there are common characteristics in the acoustics and artic-ulation of emotional speech in such different languages as American English andJapanese, the tentative results from this study (based on one speaker each) suggestthere are common characteristics. In terms of acoustics, both speakers raised F0 andtended to change F1 and voice quality. In terms of articulation, both speakers retractedtheir upper and lower lips and lowered their jaw. With regard to whether there are similarities/differences between perception of sadspeech as a function of the language: The tentative results of this study suggest that listen-ers use similar cues to rate sadness, i.e., high F0, changed F1, and changed voice quality. To briefly summarize our findings, we can say that (1) the acoustic and articula-tory characteristics of spontaneous sad speech differ from that of read speech, or imi-tated intonation speech, (2) spontaneous sad speech and imitated sad speech seem tohave similar acoustic characteristics (high F0, changed F1 as well as voice quality forboth the American English and Japanese speaker) but different articulation, (3) thereare similarities in the way they imitate sadness, i.e., lip protrusion, and (4) the articulatorycharacteristics of imitated sad speech tend to show better correlation with ratings ofsadness by listeners than do those of spontaneous sad speech. The method and tentative results of this study are reported here in order to serveas guidelines for investigating various acoustic and articulatory characteristics of various studies about the multicomplex richness of expressive speech, see e.g.,Schroeder [2004], Gobl and Ní Chasaide [2003] and Douglas-Cowie et al. [2003].
Acknowledgements¶
We thank NTT Communication Science Labs for allowing us to use the EMA facilities, andParham Mokhtari for his help in analyzing the acoustic American English data, specifically voice qual-ity. I also wish to thank two anonymous reviewers for their extremely helpful comments, and especially,Klaus Kohler for his encouragement to revise the manuscript in order that this proof of method researchcould be published. This study is supported by a Grant-in-Aid for Scientific Research, JapaneseMinistry of Education, Culture, Sports, Science and Technology (2002-5): 14510636 to the first author.
Appendix¶
| Cat. | Dur; ms | F0, Hz | F1, Hz | F2, Hz | AQ | Percept. |
|---|---|---|---|---|---|---|
| E | 250 | 327 | 355 | 2381 | 0.97 | 4.6 |
| IE | 370 | 335 | 342 | 2077 | 0.94 | 4.2 |
| II | 240 | 187 | 338 | 2579 | 1.42 | 1.5 |
| R | 300 | 199 | 335 | 2623 | 1.21 | 1.3 |
| Cat. | Dur; ms | F0, Hz | F1, Hz | F2, Hz | S Slope | Percept. |
|---|---|---|---|---|---|---|
| E | 210 | 190 | 796 | 1496 |
|
3.2 |
| IE | 175 | 184 | 785 | 1648 |
|
3.7 |
| R | 157 | 150 | 861 | 1682 |
|
2.4 |
| Speaker | Dependentvariable | d.f. | F | p |
|---|---|---|---|---|
| American English | duration F0 F1 AQ | 3,12 3,12 3,12 3,12 | 6.284 70.601 0.338 13.67 | p < 0.01 p < 0.000 p = 0.798 p < 0.000 |
| Japanese | duration F0 F1 spectral slope | 2,11 2,11 2,11 2,11 | 5.43 8.017 1.43 3.365 | p < 0.05 p < 0.000 p = 0.280 p = 0.072 |
| Cat. | Jx | Jy | ULx | ULy | LLx | LLy | T1x | T1y | T2x | T2y | T3x | T3y |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E | 7.24 | 12.07 | 6.64 | 14.66 | 6.45 | 13.06 | 7.85 | 13.73 | 8.87 | 15.09 | 9.951 | 15.47 |
| IE | 7.03 | 12.21 | 6.03 | 14.38 | 5.84 | 12.70 | 8.39 | 13.93 | 9.46 | 14.82 | 1.751 | 14.19 |
| II | 7.18 | 12.17 | 6.01 | 14.50 | 5.93 | 12.58 | 8.48 | 14.11 | 9.52 | 14.87 | 1.771 | 14.21 |
| R | 7.38 | 12.15 | 6.12 | 14.41 | 6.15 | 12.52 | 8.53 | 13.99 | 9.44 | 14.99 | 1.81 | 14.36 |
| Cat. | Jx | Jy | ULx | ULy | LLx | LLy | T1x | T1y | T2x | T2y | T3x | T3y |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| E | 7.78 | 12.63 | 5.92 | 15.12 | 6.51 | 13.13 | 8.81 | 14.12 | 9.96 | 14.62 | ||
| IE | 8.18 | 12.81 | 5.37 | 15.42 | 6.19 | 13.42 | 9.34 | 14.14 | 10.04 | 14.79 | ||
| R | 8.25 | 12.64 | 5.44 | 15.31 | 6.39 | 13.08 | 9.24 | 14.05 | 10.00 | 14.89 |
| Speaker | Dependent variable | d.f. | F | p |
|---|---|---|---|---|
| American English | ULx ULy LLx LLy Jx Jy T1x T1y T2x T2y T3x T3y | 3,12 3,12 3,12 3,12 3,12 3,12 3,12 3,12 3,12 3,12 3,12 3,12 | 63.087 2.257 26.652 14.137 21.922 4.676 43.776 4.608 17.189 3.724 107.417 393.784 | p < 0.000 p = 0.134 p < 0.000 p < 0.000 p < 0.000 p < 0.05 p < 0.000 p < 0.05 p < 0.000 p = 0.042 p < 0.000 p < 0.000 |
| Japanese | ULx ULy LLx LLy Jx Jy T1x T1y T2x T2y | 2,11 2,11 2,11 2,11 2,11 2,11 2,11 2,11 2,11 2,11 | 725.195 200.83 59.89 20.835 62.78 14.138 9.862 0.237 0.101 0.871 | p < 0.000 p < 0.000 p < 0.000 p < 0.000 p < 0.000 p < 0.01 p < 0.01 p = 0.793 p = 0.904 p = 0.446 |
References¶
| [1] | Alku, P.; Backstrom, T.; Vilkman, E.: Normalized amplitude quotient for parameterization of the glottal flow. J. acoust. Soc. Am. 112: 701-710 (2002). |
| [2] | Alku, P.; Vilkman, E.: Amplitude domain quotient for characterization of the glottal volume velocity waveform estimated by inverse filtering. Speech Com. 18: 131-138 (1996). |
| [3] | Broad, D.J.; Clermont, F.: Formant estimation by linear transformation of the LPC cepstrum. J. acoust. Soc. Am. 86: 2013-2017 (1986). |
| [4] | Brown, W.A.; Sirota, A.D.; Niaura, R.; Engebretson, T.O.: Endocrine correlates of sadness and elation. Psychosom. Med. 55: 458-467 (1993). |
| [5] | Bühler, K.: Sprachtheorie; 2nd ed. (Fischer, Stuttgart 1965). |
| [6] | Campbell, N.; Erickson, D.: What do people hear? A study of the perception of non-verbal affective information in conversational speech. J. phonet. Soc. Japan 8: 9-28 (2004). |
| [7] | Childers, D.G.; Lee, C.K.: Vocal quality factors: analysis, synthesis, perception. J. acoust. Soc. Am. 90: 2394-2410(1991). |
| [8] | Cowie, R.; Douglas-Cowie, E.; Schroeder, M.(eds.): Proceedings of the ISCA Workshop on Speech and Emotion: A Conceptual Framework for Research, Belfost (2000). |
| [9] | Darwin, C.: The expression of the emotions in man and animals; 3rd ed. (Oxford University Press, Oxford 1998). |
| [10] | Douglas-Cowie, E.; Campbell, N.; Cowie, R.; Roach, P.: Emotional speech: towards a new generation of databases. Speech Commun. 40: spec. issue Speech and Emotion, pp. 33-60 (2003). |
| [11] | Eldred, S.H.; Price, D.B.: A linguistic evaluation of feeling states in psychotherapy. Psychiatry 21: 115-121 (1958). |
| [12] | Erickson, D.: Articulation of extreme formant patterns for emphasized vowels. Phonetica 59: 134-149 (2002). |
| [13] | Erickson, D.: Expressive speech: production, perception and application to speech synthesis. J. acoust. Soc. Japan 26: 4 (2005). |
| [14] | Erickson, D.; Abramson, A.; Maekawa, K.; Kaburagi, T.: Articulatory characteristics of emotional utterances in spoken English. Proc. Int. Conf. Spoken Lang. Processing, vol 2, pp. 365-368 (2000). |
| [15] | Erickson, D.; Bauer, H.; Fujimura, O.: Non-F0 correlates of prosody in free conversation. J. acoust. Soc. Am. 88: S128 (1990). |
| [16] | Erickson, D.; Fujimura, O.; Pardo, B.: Articulatory correlates of prosodic control: emotion versus emphasis. Lang. Speech 41: spec. issue Prosody and Conversation, pp. 399-417 (1998). |
| [17] | Erickson, D.; Fujino, A.; Mochida, T.; Menezes, C.; Yoshida, K.; Shibuya, Y: Articulation of sad speech: comparison of American English and Japanese. Acoust. Soc. Japan, Fall Meeting, 2004a. |
| [18] | Erickson, D.; Menezes, C.; Fujino, A.: Sad speech: some acoustic and articulatory characteristics. Proc. 6th Int. Semin. Speech Prod., Sydney, Dec. 2003a. |
| [19] | Erickson, D.; Menezes, C.; Fujino, A.: Some articulatory measurements of real sadness (ThA3101p.3) Proc. Int. Conf. Spoken Lang. Processing, Jeju, Oct 2004b. |
| [20] | Erickson, D.; Mokhtari, P.; Menezes, C.; Fujino, A.: Voice quality and other acoustic changes in sad speech (grief). IEICE Tech. Rep. SP2003 June. ATR: 43-48 (2003b). |
| [21] | Erickson, D.; Yoshida, K.; Mochida, T.; Shibuya, Y.: Acoustic and articulatory analysis of sad Japanese speech. Phonet. Soc. Japan, Fall Meeting, 2004c. |
| [22] | Fant, G.; Kruckenberg, A.; Liljencrants, J.; Bavergard, M.: Voice source parameters in continuous speech. Transformation of LF parameters. Proc. Int. Conf. Spoken Lang. Processing, 1994, pp. 1451-1454. |
| [23] | Fujisaki, H.: Information, prosody, and modelling - with emphasis on tonal features of speech. Proc. Speech Prosody 2004, Nara 2004, pp. 1-10. |
| [24] | Gerratt, B.; Kreiman, J.: Toward a taxonomy of nonmodal phonation, J. Phonet. 29: 365-381 (2001). |
| [25] | Gobl, C.; Ní Chasaide, A.: The role of voice quality in communicating emotion, mood, and attitude. Speech Commun. 40: 189-212 (2003). |
| [26] | Hanson, H.M.; Stevens, K.N.; Kuo, H.-K.J.; Chen, M.Y.; Slifka, J.: Towards a model of phonation. J. Phonet. 29: 451-480 (2001). |
| [27] | Iida, A.: A study on corpus-based speech synthesis with emotion; thesis, Keio (2000). |
| [28] | Ishii, C.T.: A new acoustic measure for aspiration noise detection. (WeA501p.10) Proc. Int. Conf. Spoken Lang. Processing, Jeju, Oct. 2004. |
| [29] | Jackson, M.; Ladefoged, P.; Huffman, M.K.; Antoñanzas-Barroso, N.: Measures of spectral tilt. UCLA Working Papers Phonet 61: 72-78 (1985). |
| [30] | Johnson, K.: Acoustic and auditory phonetics (Blackwell Publishing, Malden 2003). |
| [31] | Kaburagi, T.; Honda, M.: Calibration methods of voltage-to-distance function for an electromagnetic articulometer (EMA) system J. acoust. Soc. Am. 111: 1414-1421 (1997). |
| [32] | Klatt, D.; Klatt, L.: Analysis, synthesis and perception of voice quality variati`ons among female and male talkers. J. acoust. Soc. Am. 87: 820-857 (1990). |
| [33] | Maekawa, K.; Kagomiya, T.; Honda, M.; Kaburagi, T.; Okadome, T.: Production of paralinguistic information: from on articulatory point of view. Acoust. Soc. Japan: 257-258 (1999). |
| [34] | Mazo, M.; Erickson, D.; Harvey, T.: Emotion and expression, temporal date on voice quality in Russian lament. 8th Vocal Fold Physiology Conference, Kurume 1995, pp. 173-187. |
| [35] | Menezes, C.: Rhythmic pattern of American English: An articulatory and acoustic study; PhD Columbus (2003). 24 Phonetica 2006;63:1-25 |
| [36] | Erickson/Yoshida/Menezes/Fujino/Mochida/Shibuya Menezes, C.: Changes in phrasing in semi-spontaneous emotional speech: articulatory evidences. J. Phonet. Soc. Japan 8: 45-59 (2004). |
| [37] | Mitchell, C.J.; Menezes, C.; Williams, J.D.; Pardo, B.; Erickson, D.; Fujimura, O.: Changes in syllable and bound- ary strengths due to irritation. ISCA Workshop on Speech and Emotion, Belfast 2000. |
| [38] | Mokhtari, P.; Campbell, N.: Perceptual validation of a voice quality parameter AQ automatically measured in acoustic islands of reliability. Acoust. Soc. Japan: 401-402 (2002). |
| [39] | Mokhtari, P.; Campbell, N: Automatic measurement of pressed/breathy phonation at acoustic centres of reliability incontinuous speech. Proc. IEICE Trans. Information Syst E-86-D: Spec. Issue on Speech Information,pp. 574-582 (2003). |
| [40] | Mokhtari, P.; Iida, A.; Campbell, N.: Some articulatory correlates of emotion variability in speech: a preliminary study on spoken Japanese vowels. Proc. Int. Conf. Speech Processing, Taejon 2001, pp. 431-436. |
| [41] | Ní Chasaide, A.; Gobl, C.: Voice source variation; in Hardcastle, Laver, The handbook of phonetic sciences (Blackwell, Oxford 1997), pp. 427-461. |
| [42] | Redi, L.; Shattuck-Hufnagel, S.: Variation in the realization of glottalization in normal speakers. J. Phonet. 29: 407-429 (2001). |
| [43] | Sadanobu, T.: A natural history of Japanese pressed voice. J. Phonet. Soc. Japan 8: 29-44 (2004). |
| [44] | Scherer, K.R.: Vocal communication of emotion: A review of research paradigms. Speech Commun. 40: 227-256 (2003). |
| [45] | Scherer, K.R.; Nonlinguistic vocal indicators of emotion and psychopathology; in Izard, Emotions in personality and psychopathology, pp. 493-529 (Plenum Press, New York 1979). |
| [46] | Scherer, K.R.; Banse, R.; Wallbott, H.G.; Goldbeck, T.: Vocal cues in emotion encoding and decoding. Motivation Emotion 15: 123-148 (1991). |
| [47] | Schroeder, M.: Speech and emotion research: an overview of research frameworks and a dimensional approach to emotional speech synthesis; thesis 7, Saarbrücken (2004). |
| [48] | Schroeder, M.; Aubergé, V.; Cathiard, M.A.: Can we hear smile? Proc. 5th Int. Conf. Spoken Lang. Processing, Sydney 1998. Sad Speech Phonetica 2006;63:1-25 25 |
All in-text references underlined in blue are linked to publications on ResearchGate, letting you access and read them immediately.